
Convolutional Neural Networks and Computer Vision with TensorFlow
Published:
This blog post provides a comprehensive guide to developing Convolutional Neural Networks (CNN) models using TensorFlow. The objective of the post is to help readers understand the basics of developing CNN models using TensorFlow. The post is divided into two main sections, binary classification of images and multi-class classification of images. These sections cover various topics such as image preprocessing, model architecture, and model training, and evaluation.
The post is compatible with Google Colaboratory and can be accessed through this link:
![]()
Convolutional Neural Networks and Computer Vision with TensorFlow
- Developed by Armin Norouzi
Compatible with Google Colaboratory- Tensorflow 2.8.2
- Objective: Develop CNN models using Tensorflow
Table of content:
- Binary Classification of Images
- Multi-class classification of Images
Geting data and being familiar with data
Get the data
The images we’re going to work with are from the Food-101 dataset, a collection of 101 different categories of 101,000 (1000 images per category) real-world images of food dishes.
To begin, we’re only going to use two of the categories, pizza 🍕 and steak 🥩 and build a binary classifier.
import zipfile
# Download zip file of pizza_steak images
!wget https://gitlab.com/arminny/ml_course_datasets/-/raw/main/pizza_steak.zip
# Unzip the downloaded file
zip_ref = zipfile.ZipFile("pizza_steak.zip", "r")
zip_ref.extractall()
zip_ref.close()
--2022-09-21 14:00:41-- https://gitlab.com/arminny/ml_course_datasets/-/raw/main/pizza_steak.zip
Resolving gitlab.com (gitlab.com)... 172.65.251.78, 2606:4700:90:0:f22e:fbec:5bed:a9b9
Connecting to gitlab.com (gitlab.com)|172.65.251.78|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 109540975 (104M) [application/octet-stream]
Saving to: ‘pizza_steak.zip’
pizza_steak.zip 100%[===================>] 104.47M 49.7MB/s in 2.1s
2022-09-21 14:00:43 (49.7 MB/s) - ‘pizza_steak.zip’ saved [109540975/109540975]
Inspect the data
- A
traindirectory which contains all of the images in the training dataset with subdirectories each named after a certain class containing images of that class. - A
testdirectory with the same structure as thetraindirectory.
Example of file structure
pizza_steak <- top level folder
└───train <- training images
│ └───pizza
│ │ │ 1008104.jpg
│ │ │ 1638227.jpg
│ │ │ ...
│ └───steak
│ │ 1000205.jpg
│ │ 1647351.jpg
│ │ ...
│
└───test <- testing images
│ └───pizza
│ │ │ 1001116.jpg
│ │ │ 1507019.jpg
│ │ │ ...
│ └───steak
│ │ 100274.jpg
│ │ 1653815.jpg
│ │ ...
Let’s inspect each of the directories we’ve downloaded.
To so do, we can use the command ls which stands for list.
!ls pizza_steak
test train
We can see we’ve got a train and test folder.
Let’s see what’s inside one of them.
!ls pizza_steak/train/
pizza steak
import os
# Walk through pizza_steak directory and list number of files
for dirpath, dirnames, filenames in os.walk("pizza_steak"):
print(f"There are {len(dirnames)} directories and {len(filenames)} images in '{dirpath}'.")
There are 2 directories and 0 images in 'pizza_steak'.
There are 2 directories and 0 images in 'pizza_steak/test'.
There are 0 directories and 250 images in 'pizza_steak/test/steak'.
There are 0 directories and 250 images in 'pizza_steak/test/pizza'.
There are 2 directories and 0 images in 'pizza_steak/train'.
There are 0 directories and 750 images in 'pizza_steak/train/steak'.
There are 0 directories and 750 images in 'pizza_steak/train/pizza'.
# Another way to find out how many images are in a file
num_steak_images_train = len(os.listdir("pizza_steak/train/steak"))
num_steak_images_train
750
# Get the class names (programmatically, this is much more helpful with a longer list of classes)
import pathlib
import numpy as np
data_dir = pathlib.Path("pizza_steak/train/") # turn our training path into a Python path
class_names = np.array(sorted([item.name for item in data_dir.glob('*')])) # created a list of class_names from the subdirectories
print(class_names)
['pizza' 'steak']
# View an image
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import random
def view_random_image(target_dir, target_class):
# Setup target directory (we'll view images from here)
target_folder = target_dir+target_class
# Get a random image path
random_image = random.sample(os.listdir(target_folder), 1)
# Read in the image and plot it using matplotlib
img = mpimg.imread(target_folder + "/" + random_image[0])
plt.imshow(img)
plt.title(target_class)
plt.axis("off");
print(f"Image shape: {img.shape}") # show the shape of the image
return img
# View a random image from the training dataset
img = view_random_image(target_dir="pizza_steak/train/",
target_class="steak")
Image shape: (512, 512, 3)

After going through a dozen or so images from the different classes, you can start to get an idea of what we’re working with.
The entire Food101 dataset comprises of similar images from 101 different classes.
You might’ve noticed we’ve been printing the image shape alongside the plotted image.
This is because the way our computer sees the image is in the form of a big array (tensor).
# View the image shape
img.shape # returns (width, height, colour channels)
(512, 512, 3)
Looking at the image shape more closely, you’ll see it’s in the form (Width, Height, Colour Channels).
In our case, the width and height vary but because we’re dealing with colour images, the colour channels value is always 3. This is for different values of red, green and blue (RGB) pixels.
You’ll notice all of the values in the img array are between 0 and 255. This is because that’s the possible range for red, green and blue values.
For example, a pixel with a value red=0, green=0, blue=255 will look very blue.
So when we build a model to differentiate between our images of pizza and steak, it will be finding patterns in these different pixel values which determine what each class looks like.
A (typical) architecture of a convolutional neural network
Convolutional neural networks are no different to other kinds of deep learning neural networks in the fact they can be created in many different ways. What you see below are some components you’d expect to find in a traditional CNN.
Components of a convolutional neural network:
| Hyperparameter/Layer type | What does it do? | Typical values |
|---|---|---|
| Input image(s) | Target images you’d like to discover patterns in | Whatever you can take a photo (or video) of |
| Input layer | Takes in target images and preprocesses them for further layers | input_shape = [batch_size, image_height, image_width, color_channels] |
| Convolution layer | Extracts/learns the most important features from target images | Multiple, can create with tf.keras.layers.ConvXD (X can be multiple values) |
| Hidden activation | Adds non-linearity to learned features (non-straight lines) | Usually ReLU (tf.keras.activations.relu) |
| Pooling layer | Reduces the dimensionality of learned image features | Average (tf.keras.layers.AvgPool2D) or Max (tf.keras.layers.MaxPool2D) |
| Fully connected layer | Further refines learned features from convolution layers | tf.keras.layers.Dense |
| Output layer | Takes learned features and outputs them in shape of target labels | output_shape = [number_of_classes] (e.g. 3 for pizza, steak or sushi) |
| Output activation | Adds non-linearities to output layer | tf.keras.activations.sigmoid (binary classification) or tf.keras.activations.softmax |
Binary Classification of Images
We’ve checked out our data and found there’s 750 training images, as well as 250 test images per class and they’re all of various different shapes.
It’s time to jump straight in the deep end.
Reading the original dataset authors paper, we see they used a Random Forest machine learning model and averaged 50.76% accuracy at predicting what different foods different images had in them.
From now on, that 50.76% will be our baseline.
Note: A baseline is a score or evaluation metric you want to try and beat. Usually you’ll start with a simple model, create a baseline and try to beat it by increasing the complexity of the model. A really fun way to learn machine learning is to find some kind of modelling paper with a published result and try to beat it.
The code in the following cell replicates and end-to-end way to model our pizza_steak dataset with a convolutional neural network (CNN) using the components listed above.
There will be a bunch of things you might not recognize but step through the code yourself and see if you can figure out what it’s doing.
We’ll go through each of the steps later on in the notebook.
For reference, the model we’re using replicates TinyVGG, the computer vision architecture which fuels the CNN explainer webpage.
Resource: The architecture we’re using below is a scaled-down version of VGG-16, a convolutional neural network which came 2nd in the 2014 ImageNet classification competition.
Importing libraries
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
Preprosessing
# Set the seed
tf.random.set_seed(42)
# Preprocess data (get all of the pixel values between 1 and 0, also called scaling/normalization)
train_datagen = ImageDataGenerator(rescale=1./255)
valid_datagen = ImageDataGenerator(rescale=1./255)
# Setup the train and test directories
train_dir = "pizza_steak/train/"
test_dir = "pizza_steak/test/"
# Import data from directories and turn it into batches
train_data = train_datagen.flow_from_directory(train_dir,
batch_size=32, # number of images to process at a time
target_size=(224, 224), # convert all images to be 224 x 224
class_mode="binary", # type of problem we're working on
seed=42)
valid_data = valid_datagen.flow_from_directory(test_dir,
batch_size=32,
target_size=(224, 224),
class_mode="binary",
seed=42)
Found 1500 images belonging to 2 classes.
Found 500 images belonging to 2 classes.
Model structure
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPool2D, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import Sequential
def model_structure():
model = Sequential()
model.add(Conv2D(10, 3, strides=1, activation="relu",input_shape=(224, 224, 3), name='conv1', padding="same"))
model.add(Conv2D(10, 3, activation="relu", name='conv2', padding="same"))
model.add(MaxPool2D(2, name='MaxPool1')) # padding can also be 'same'
model.add(Conv2D(10, 3, activation="relu", name='conv3', padding="same"))
model.add(MaxPool2D(2, name='MaxPool2'))
model.add(Conv2D(10, 3, activation="relu", name='conv4', padding="same"))
model.add(MaxPool2D(2, name='MaxPool3'))
model.add(Flatten(name='Flatten'))
model.add(Dense(1, activation="sigmoid", name='Output'))
# Compile the model
model.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
print(model.summary())
return model
Hyper-parameters explaination
Here we will speak about the additional parameters present in CNNs, please refer part-I(link at the start) to learn about hyper-parameters in dense layers as they also are part of the CNN architecture.
Kernel/Filter Size: A filter is a matrix of weights with which we convolve on the input. The filter on convolution, provides a measure for how close a patch of input resembles a feature. A feature may be vertical edge or an arch,or any shape. The weights in the filter matrix are derived while training the data. Smaller filters collect as much local information as possible, bigger filters represent more global, high-level and representative information. If you think that a big amount of pixels are necessary for the network to recognize the object you will use large filters (as 11x11 or 9x9). If you think what differentiates objects are some small and local features you should use small filters (3x3 or 5x5). Note in general we use filters with odd sizes. Padding: Padding is generally used to add columns and rows of zeroes to keep the spatial sizes constant after convolution, doing this might improve performance as it retains the information at the borders. Parameters for the padding function in Keras are Same- output size is the same as input size by padding evenly left and right, but if the amount of columns to be added is odd, it will add the extra column to the right.Valid- Output size shrinks to ceil((n+f-1)/s) where ’n’ is input dimensions ‘f’ is filter size and ‘s’ is stride length. ceil rounds off the decimal to the closet higher integer, No padding occurs.
Stride: It is generally the number of pixels you wish to skip while traversing the input horizontally and vertically during convolution after each element-wise multiplication of the input weights with those in the filter. It is used to decrease the input image size considerably as after the convolution operation the size shrinks to ceil((n+f-1)/s) where ’n’ is input dimensions ‘f’ is filter size and ‘s’ is stride length. ceil rounds off the decimal to the closet higher integer.
Number of Channels: It is the equal to the number of color channels for the input but in later stages is equal to the number of filters we use for the convolution operation. The more the number of channels,more the number of filters used, more are the features learnt, and more is the chances to over-fit and vice-versa.
Pooling-layer Parameters: Pooling layers too have the same parameters as a convolution layer. Max-Pooling is generally used among all the pooling options. The objective is to down-sample an input representation (image, hidden-layer output matrix, etc.), reducing its dimensionality by keeping the max value(activated features) in the sub-regions binned.
Principles/Conventions to build a CNN architecture
The basic principle followed in building a convolutional neural network is to ‘keep the feature space wide and shallow in the initial stages of the network, and the make it narrower and deeper towards the end.’
Keeping the above principle in mind we lay down a few conventions to be followed to guide you while building your CNN architecture
Always start by using smaller filters is to collect as much local information as possible, and then gradually increase the filter width to reduce the generated feature space width to represent more global, high-level and representative information
Following the principle, the number of channels should be low in the beginning such that it detects low-level features which are combined to form many complex shapes(by increasing the number of channels) which help distinguish between classes.
The number of filters is increased to increase the depth of the feature space thus helping in learning more levels of global abstract structures. One more utility of making the feature space deeper and narrower is to shrink the feature space for input to the dense networks.
By convention the number of channels generally increase or stay the same while we progress through layers in our convolutional neural net architecture
General filter sizes used are 3x3, 5x5 and 7x7 for the convolutional layer for a moderate or small-sized images and for Max-Pooling parameters we use 2x2 or 3x3 filter sizes with a stride of 2. Larger filter sizes and strides may be used to shrink a large image to a moderate size and then go further with the convention stated.
Try using padding = same when you feel the border’s of the image might be important or just to help elongate your network architecture as padding keeps the dimensions same even after the convolution operation and therefore you can perform more convolutions without shrinking size.
Keep adding layers until you over-fit. As once we achieved a considerable accuracy in our validation set we can use regularization components like l1/l2 regularization, dropout, batch norm, data augmentation etc. to reduce over-fitting
Always use classic networks like LeNet, AlexNet, VGG-16, VGG-19 etc. as an inspiration while building the architectures for your models. By inspiration i mean follow the trend used in the architectures for example trend in the layers Conv-Pool-Conv-Pool or Conv-Conv-Pool-Conv-Conv-Pool or trend in the Number of channels 32–64–128 or 32–32-64–64 or trend in filter sizes, Max-pooling parameters etc.
Training
model_1 = model_structure()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1 (Conv2D) (None, 224, 224, 10) 280
conv2 (Conv2D) (None, 224, 224, 10) 910
MaxPool1 (MaxPooling2D) (None, 112, 112, 10) 0
conv3 (Conv2D) (None, 112, 112, 10) 910
MaxPool2 (MaxPooling2D) (None, 56, 56, 10) 0
conv4 (Conv2D) (None, 56, 56, 10) 910
MaxPool3 (MaxPooling2D) (None, 28, 28, 10) 0
Flatten (Flatten) (None, 7840) 0
Output (Dense) (None, 1) 7841
=================================================================
Total params: 10,851
Trainable params: 10,851
Non-trainable params: 0
_________________________________________________________________
None
log_dir = "logs/fit/"
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
# Fit the model
history_1 = model_1.fit(train_data,
epochs=20,
steps_per_epoch=len(train_data),
validation_data=valid_data,
validation_steps=len(valid_data),
verbose = 0,
callbacks=[tensorboard_callback])
%load_ext tensorboard
%tensorboard --logdir logs/fit
Output hidden; open in https://colab.research.google.com to view.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 7))
plt.plot(history_1.history['accuracy'], label = "accuracy")
plt.plot(history_1.history['val_accuracy'], label= "val accuracy")
plt.xlabel("Epochs")
plt.ylabel("loss/accuracy")
plt.legend()
plt.show()
plt.figure(figsize=(10, 7))
plt.plot(history_1.history['loss'], label = "loss")
plt.plot(history_1.history['val_loss'], label= "val_loss")
plt.xlabel("Epochs")
plt.ylabel("loss/accuracy")
plt.legend()
plt.show()
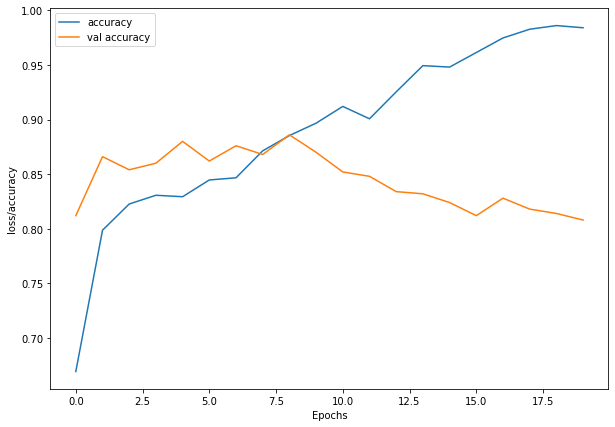
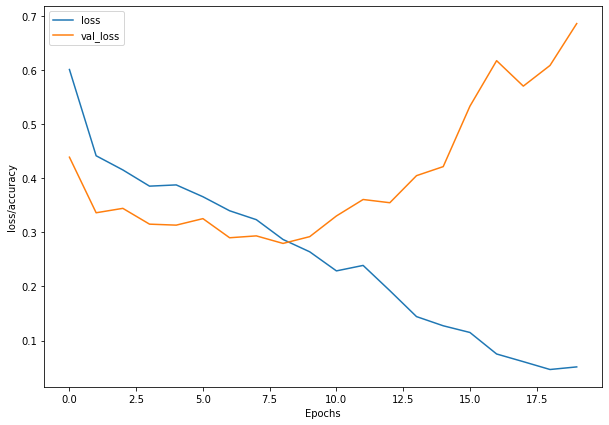
What do you notice about the names of model_1’s layers and the layer names at the top of the CNN explainer website?
I’ll let you in on a little secret: we’ve replicated the exact architecture they use for their model demo.
Look at you go! You’re already starting to replicate models you find in the wild.
Now there are a few new things here we haven’t discussed, namely:
- The
ImageDataGeneratorclass and therescaleparameter - The
flow_from_directory()method- The
batch_sizeparameter - The
target_sizeparameter
- The
Conv2Dlayers (and the parameters which come with them)MaxPool2Dlayers (and their parameters).- The
steps_per_epochandvalidation_stepsparameters in thefit()function
Before we dive into each of these, let’s see what happens if we try to fit a model we’ve worked with previously to our data.
from tensorflow._api.v2.random import shuffle
# Create ImageDataGenerator training instance with data augmentation
train_datagen_augmented = ImageDataGenerator(rescale=1/255.,
rotation_range=20, # rotate the image slightly between 0 and 20 degrees (note: this is an int not a float)
shear_range=0.2, # shear the image
zoom_range=0.2, # zoom into the image
width_shift_range=0.2, # shift the image width ways
height_shift_range=0.2, # shift the image height ways
horizontal_flip=True) # flip the image on the horizontal axis
# Create ImageDataGenerator training instance without data augmentation
train_datagen = ImageDataGenerator(rescale=1/255.)
# Create ImageDataGenerator test instance without data augmentation
test_datagen = ImageDataGenerator(rescale=1/255.)
# Import data from directories and turn it into batches
train_data_augmented = train_datagen_augmented.flow_from_directory(train_dir,
batch_size=32, # number of images to process at a time
target_size=(224, 224), # convert all images to be 224 x 224
class_mode="binary", # type of problem we're working on
seed=42,
shuffle = True)
valid_data = valid_datagen.flow_from_directory(test_dir,
batch_size=32,
target_size=(224, 224),
class_mode="binary",
seed=42)
Found 1500 images belonging to 2 classes.
Found 500 images belonging to 2 classes.
model_2 = model_structure()
# Fit the model
history_2 = model_2.fit(train_data_augmented,
epochs=20,
steps_per_epoch=len(train_data),
validation_data=valid_data,
validation_steps=len(valid_data),
verbose = 0)
plt.figure(figsize=(10, 7))
plt.plot(history_1.history['accuracy'], label = "accuracy")
plt.plot(history_1.history['val_accuracy'], label= "val accuracy")
plt.xlabel("Epochs")
plt.ylabel("loss/accuracy")
plt.legend()
plt.show()
plt.figure(figsize=(10, 7))
plt.plot(history_1.history['loss'], label = "loss")
plt.plot(history_1.history['val_loss'], label= "val_loss")
plt.xlabel("Epochs")
plt.ylabel("loss/accuracy")
plt.legend()
plt.show()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1 (Conv2D) (None, 224, 224, 10) 280
conv2 (Conv2D) (None, 224, 224, 10) 910
MaxPool1 (MaxPooling2D) (None, 112, 112, 10) 0
conv3 (Conv2D) (None, 112, 112, 10) 910
MaxPool2 (MaxPooling2D) (None, 56, 56, 10) 0
conv4 (Conv2D) (None, 56, 56, 10) 910
MaxPool3 (MaxPooling2D) (None, 28, 28, 10) 0
Flatten (Flatten) (None, 7840) 0
Output (Dense) (None, 1) 7841
=================================================================
Total params: 10,851
Trainable params: 10,851
Non-trainable params: 0
_________________________________________________________________
None
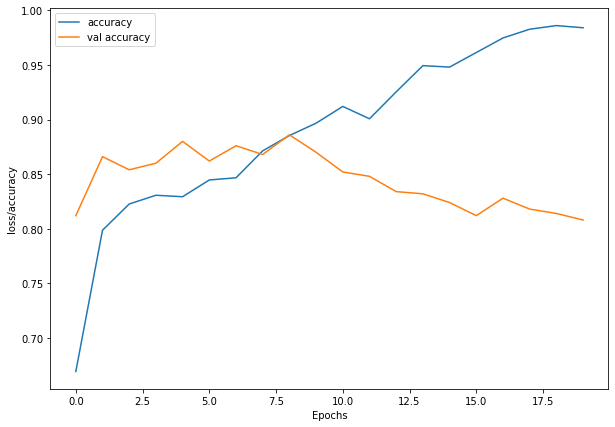
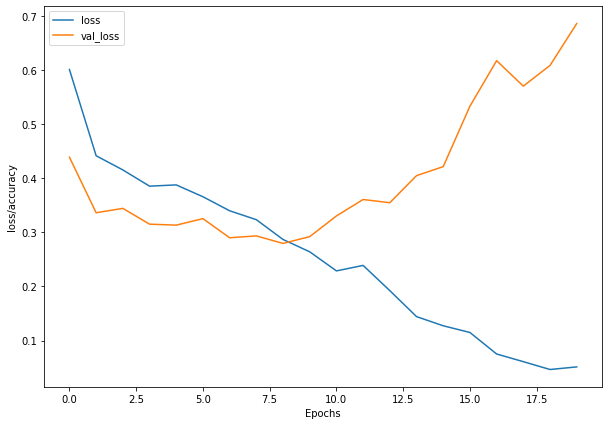
def model_structure_2():
model = Sequential()
model.add(Conv2D(10, 3, strides=1, activation="relu",input_shape=(224, 224, 3), name='conv1'))
model.add(Conv2D(32, 3, activation="relu", name='conv2'))
model.add(Conv2D(10, 3, activation="relu", name='conv3'))
model.add(Conv2D(10, 3, activation="relu", name='conv4'))
model.add(MaxPool2D(3, name='MaxPool2'))
model.add(Flatten(name='Flatten'))
model.add(Dense(1, activation="sigmoid", name='Output'))
# Compile the model
model.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
metrics=["accuracy"])
print(model.summary())
return model
# Create ImageDataGenerator training instance with data augmentation
train_datagen_augmented = ImageDataGenerator(rescale=1/255.,
rotation_range=20, # rotate the image slightly between 0 and 20 degrees (note: this is an int not a float)
shear_range=0.2, # shear the image
zoom_range=0.2, # zoom into the image
# width_shift_range=0.2, # shift the image width ways
# height_shift_range=0.2, # shift the image height ways
horizontal_flip=True) # flip the image on the horizontal axis
# Create ImageDataGenerator training instance without data augmentation
train_datagen = ImageDataGenerator(rescale=1/255.)
# Create ImageDataGenerator test instance without data augmentation
test_datagen = ImageDataGenerator(rescale=1/255.)
# Import data from directories and turn it into batches
train_data_augmented = train_datagen_augmented.flow_from_directory(train_dir,
batch_size=32, # number of images to process at a time
target_size=(224, 224), # convert all images to be 224 x 224
class_mode="binary", # type of problem we're working on
seed=42)
valid_data = valid_datagen.flow_from_directory(test_dir,
batch_size=32,
target_size=(224, 224),
class_mode="binary",
seed=42)
Found 1500 images belonging to 2 classes.
Found 500 images belonging to 2 classes.
model_3 = model_structure_2()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1 (Conv2D) (None, 222, 222, 10) 280
conv2 (Conv2D) (None, 220, 220, 32) 2912
conv3 (Conv2D) (None, 218, 218, 10) 2890
conv4 (Conv2D) (None, 216, 216, 10) 910
MaxPool2 (MaxPooling2D) (None, 72, 72, 10) 0
Flatten (Flatten) (None, 51840) 0
Output (Dense) (None, 1) 51841
=================================================================
Total params: 58,833
Trainable params: 58,833
Non-trainable params: 0
_________________________________________________________________
None
# Fit the model
history_3 = model_3.fit(train_data_augmented,
epochs=20,
steps_per_epoch=len(train_data),
validation_data=valid_data,
validation_steps=len(valid_data),
verbose = 1)
plt.figure(figsize=(10, 7))
plt.plot(history_1.history['accuracy'], label = "accuracy")
plt.plot(history_1.history['val_accuracy'], label= "val accuracy")
plt.xlabel("Epochs")
plt.ylabel("loss/accuracy")
plt.legend()
plt.show()
plt.figure(figsize=(10, 7))
plt.plot(history_1.history['loss'], label = "loss")
plt.plot(history_1.history['val_loss'], label= "val_loss")
plt.xlabel("Epochs")
plt.ylabel("loss/accuracy")
plt.legend()
plt.show()
Epoch 1/20
47/47 [==============================] - 27s 530ms/step - loss: 0.6304 - accuracy: 0.6793 - val_loss: 0.5704 - val_accuracy: 0.6740
Epoch 2/20
47/47 [==============================] - 23s 483ms/step - loss: 0.5210 - accuracy: 0.7553 - val_loss: 0.4640 - val_accuracy: 0.7860
Epoch 3/20
47/47 [==============================] - 23s 482ms/step - loss: 0.4919 - accuracy: 0.7633 - val_loss: 0.4821 - val_accuracy: 0.7600
Epoch 4/20
47/47 [==============================] - 23s 481ms/step - loss: 0.4608 - accuracy: 0.7887 - val_loss: 0.3956 - val_accuracy: 0.8180
Epoch 5/20
47/47 [==============================] - 23s 486ms/step - loss: 0.4487 - accuracy: 0.7893 - val_loss: 0.3810 - val_accuracy: 0.8240
Epoch 6/20
47/47 [==============================] - 23s 493ms/step - loss: 0.4303 - accuracy: 0.8147 - val_loss: 0.3673 - val_accuracy: 0.8400
Epoch 7/20
47/47 [==============================] - 23s 487ms/step - loss: 0.4475 - accuracy: 0.7893 - val_loss: 0.3635 - val_accuracy: 0.8280
Epoch 8/20
47/47 [==============================] - 24s 508ms/step - loss: 0.4248 - accuracy: 0.8027 - val_loss: 0.3538 - val_accuracy: 0.8520
Epoch 9/20
47/47 [==============================] - 23s 484ms/step - loss: 0.4231 - accuracy: 0.8067 - val_loss: 0.3726 - val_accuracy: 0.8340
Epoch 10/20
47/47 [==============================] - 23s 482ms/step - loss: 0.4178 - accuracy: 0.8073 - val_loss: 0.3475 - val_accuracy: 0.8580
Epoch 11/20
47/47 [==============================] - 23s 481ms/step - loss: 0.4162 - accuracy: 0.8207 - val_loss: 0.3340 - val_accuracy: 0.8520
Epoch 12/20
47/47 [==============================] - 23s 481ms/step - loss: 0.4091 - accuracy: 0.8140 - val_loss: 0.3428 - val_accuracy: 0.8580
Epoch 13/20
47/47 [==============================] - 23s 481ms/step - loss: 0.3961 - accuracy: 0.8253 - val_loss: 0.3372 - val_accuracy: 0.8680
Epoch 14/20
47/47 [==============================] - 23s 482ms/step - loss: 0.4055 - accuracy: 0.8167 - val_loss: 0.3228 - val_accuracy: 0.8720
Epoch 15/20
47/47 [==============================] - 24s 502ms/step - loss: 0.3946 - accuracy: 0.8233 - val_loss: 0.3233 - val_accuracy: 0.8660
Epoch 16/20
47/47 [==============================] - 23s 481ms/step - loss: 0.4020 - accuracy: 0.8213 - val_loss: 0.3697 - val_accuracy: 0.8360
Epoch 17/20
47/47 [==============================] - 23s 481ms/step - loss: 0.3964 - accuracy: 0.8227 - val_loss: 0.3155 - val_accuracy: 0.8860
Epoch 18/20
47/47 [==============================] - 23s 481ms/step - loss: 0.3960 - accuracy: 0.8200 - val_loss: 0.3065 - val_accuracy: 0.8740
Epoch 19/20
47/47 [==============================] - 23s 482ms/step - loss: 0.4086 - accuracy: 0.8173 - val_loss: 0.3119 - val_accuracy: 0.8860
Epoch 20/20
47/47 [==============================] - 23s 482ms/step - loss: 0.3864 - accuracy: 0.8327 - val_loss: 0.3154 - val_accuracy: 0.8760
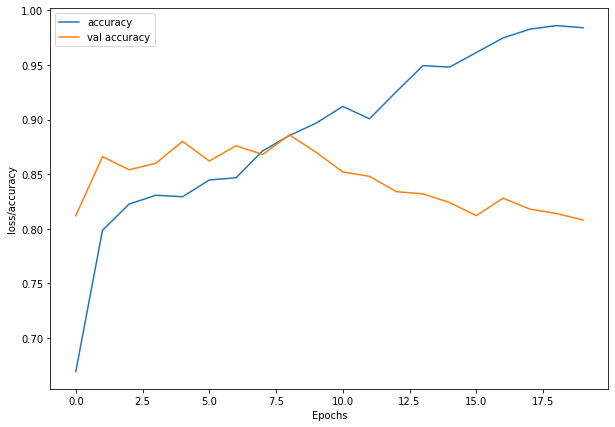
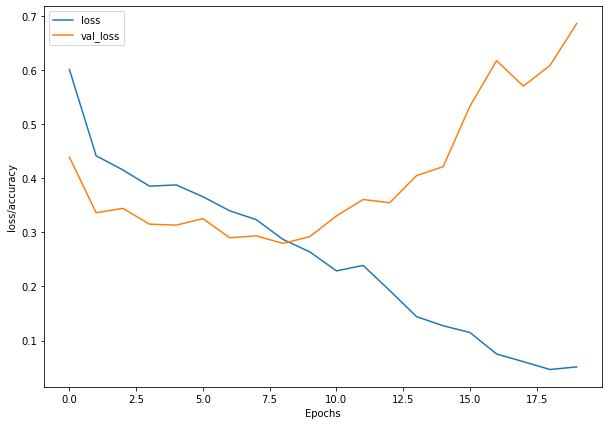
Multi-class Classification
We’ve referenced the TinyVGG architecture from the CNN Explainer website multiple times through this notebook, however, the CNN Explainer website works with 10 different image classes, where as our current model only works with two classes (pizza and steak).
How about we go through those steps again, except this time, we’ll work with 10 different types of food.
- Check data
- Preprocess the data (prepare it for a model)
- Create a model (start with a baseline)
- Fit the model
- Evaluate the model
- Adjust different parameters and improve model (try to beat your baseline)
- Repeat until satisfied
1. Import and checking data
Again, we’ve got a subset of the Food101 dataset. In addition to the pizza and steak images, we’ve pulled out another eight classes.
import zipfile
# Download zip file of 10_food_classes images
!wget https://gitlab.com/arminny/ml_course_datasets/-/raw/main/10_food_classes_all_data.zip
# Unzip the downloaded file
zip_ref = zipfile.ZipFile("10_food_classes_all_data.zip", "r")
zip_ref.extractall()
zip_ref.close()
--2022-09-08 15:11:33-- https://gitlab.com/arminny/ml_course_datasets/-/raw/main/10_food_classes_all_data.zip
Resolving gitlab.com (gitlab.com)... 172.65.251.78, 2606:4700:90:0:f22e:fbec:5bed:a9b9
Connecting to gitlab.com (gitlab.com)|172.65.251.78|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 519183241 (495M) [application/octet-stream]
Saving to: ‘10_food_classes_all_data.zip’
10_food_classes_all 100%[===================>] 495.13M 78.3MB/s in 7.3s
2022-09-08 15:11:41 (68.0 MB/s) - ‘10_food_classes_all_data.zip’ saved [519183241/519183241]
Now let’s check out all of the different directories and sub-directories in the 10_food_classes file.
import os
# Walk through 10_food_classes directory and list number of files
for dirpath, dirnames, filenames in os.walk("10_food_classes_all_data"):
print(f"There are {len(dirnames)} directories and {len(filenames)} images in '{dirpath}'.")
There are 2 directories and 0 images in '10_food_classes_all_data'.
There are 10 directories and 0 images in '10_food_classes_all_data/test'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/pizza'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/chicken_wings'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/grilled_salmon'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/hamburger'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/chicken_curry'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/fried_rice'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/steak'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/ramen'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/sushi'.
There are 0 directories and 250 images in '10_food_classes_all_data/test/ice_cream'.
There are 10 directories and 0 images in '10_food_classes_all_data/train'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/pizza'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/chicken_wings'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/grilled_salmon'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/hamburger'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/chicken_curry'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/fried_rice'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/steak'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/ramen'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/sushi'.
There are 0 directories and 750 images in '10_food_classes_all_data/train/ice_cream'.
We’ll now setup the training and test directory paths.
train_dir = "10_food_classes_all_data/train/"
test_dir = "10_food_classes_all_data/test/"
And get the class names from the subdirectories.
# Get the class names for our multi-class dataset
import pathlib
import numpy as np
data_dir = pathlib.Path(train_dir)
class_names = np.array(sorted([item.name for item in data_dir.glob('*')]))
print(class_names)
['chicken_curry' 'chicken_wings' 'fried_rice' 'grilled_salmon' 'hamburger'
'ice_cream' 'pizza' 'ramen' 'steak' 'sushi']
How about we visualize an image from the training set?
# View a random image from the training dataset
import random
img = view_random_image(target_dir=train_dir,
target_class=random.choice(class_names)) # get a random class name
Image shape: (512, 512, 3)

2. Preprocess the data (prepare it for a model)
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Rescale the data and create data generator instances
train_datagen = ImageDataGenerator(rescale=1/255.)
test_datagen = ImageDataGenerator(rescale=1/255.)
# Load data in from directories and turn it into batches
train_data = train_datagen.flow_from_directory(train_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical') # changed to categorical
test_data = train_datagen.flow_from_directory(test_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
Found 7500 images belonging to 10 classes.
Found 2500 images belonging to 10 classes.
As with binary classifcation, we’ve creator image generators. The main change this time is that we’ve changed the class_mode parameter to 'categorical' because we’re dealing with 10 classes of food images.
Everything else like rescaling the images, creating the batch size and target image size stay the same.
3. Create a model (start with a baseline)
We can use the same model (TinyVGG) we used for the binary classification problem for our multi-class classification problem with a couple of small tweaks.
Namely:
- Changing the output layer to use have 10 ouput neurons (the same number as the number of classes we have).
- Changing the output layer to use
'softmax'activation instead of'sigmoid'activation. - Changing the loss function to be
'categorical_crossentropy'instead of'binary_crossentropy'.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPool2D, Flatten, Dense
# Create our model (a clone of model_8, except to be multi-class)
def model_structure_TinyVGG(num_filter, filter_size):
model = Sequential()
model.add(Conv2D(num_filter, filter_size, activation='relu', input_shape=(224, 224, 3)))
model.add(Conv2D(num_filter, filter_size, activation='relu'))
model.add(MaxPool2D())
model.add(Conv2D(num_filter, filter_size, activation='relu'))
model.add(Conv2D(num_filter, filter_size, activation='relu'))
model.add(MaxPool2D())
model.add(Flatten())
model.add(Dense(10, activation='softmax'))
# Compile the model
model.compile(loss="categorical_crossentropy", # changed to categorical_crossentropy
optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
metrics=["accuracy"])
print(model.summary())
return model
model_4 = model_structure_TinyVGG(10, 3)
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 222, 222, 10) 280
conv2d_1 (Conv2D) (None, 220, 220, 10) 910
max_pooling2d (MaxPooling2D (None, 110, 110, 10) 0
)
conv2d_2 (Conv2D) (None, 108, 108, 10) 910
conv2d_3 (Conv2D) (None, 106, 106, 10) 910
max_pooling2d_1 (MaxPooling (None, 53, 53, 10) 0
2D)
flatten (Flatten) (None, 28090) 0
dense (Dense) (None, 10) 280910
=================================================================
Total params: 283,920
Trainable params: 283,920
Non-trainable params: 0
_________________________________________________________________
None
4. Fit a model
Now we’ve got a model suited for working with multiple classes, let’s fit it to our data.
# Fit the model
history_4 = model_4.fit(train_data, # now 10 different classes
epochs=5,
steps_per_epoch=len(train_data),
validation_data=test_data,
validation_steps=len(test_data))
Epoch 1/5
235/235 [==============================] - 48s 198ms/step - loss: 2.1678 - accuracy: 0.2036 - val_loss: 2.0095 - val_accuracy: 0.2844
Epoch 2/5
235/235 [==============================] - 45s 192ms/step - loss: 1.9636 - accuracy: 0.3109 - val_loss: 1.9276 - val_accuracy: 0.3060
Epoch 3/5
235/235 [==============================] - 45s 191ms/step - loss: 1.8769 - accuracy: 0.3475 - val_loss: 1.8819 - val_accuracy: 0.3364
Epoch 4/5
235/235 [==============================] - 46s 195ms/step - loss: 1.7963 - accuracy: 0.3848 - val_loss: 1.8692 - val_accuracy: 0.3388
Epoch 5/5
235/235 [==============================] - 45s 193ms/step - loss: 1.7429 - accuracy: 0.4131 - val_loss: 1.8309 - val_accuracy: 0.3556
Why do you think each epoch takes longer than when working with only two classes of images?
It’s because we’re now dealing with more images than we were before. We’ve got 10 classes with 750 training images and 250 validation images each totalling 10,000 images. Where as when we had two classes, we had 1500 training images and 500 validation images, totalling 2000.
The intuitive reasoning here is the more data you have, the longer a model will take to find patterns.
5. Evaluate the model
Woohoo! We’ve just trained a model on 10 different classes of food images, let’s see how it went.
# Evaluate on the test data
model_4.evaluate(test_data)
79/79 [==============================] - 11s 140ms/step - loss: 1.8309 - accuracy: 0.3556
[1.8308897018432617, 0.3555999994277954]
def plot_loss(history):
plt.figure(figsize=(10, 7))
plt.plot(history.history['accuracy'], label = "accuracy")
plt.plot(history.history['val_accuracy'], label= "val accuracy")
plt.xlabel("Epochs")
plt.ylabel("accuracy")
plt.legend()
plt.show()
plt.figure(figsize=(10, 7))
plt.plot(history.history['loss'], label = "loss")
plt.plot(history.history['val_loss'], label= "val_loss")
plt.xlabel("Epochs")
plt.ylabel("loss")
plt.legend()
plt.show()
# Check out the model's loss curves on the 10 classes of data (note: this function comes from above in the notebook)
plot_loss(history_4)
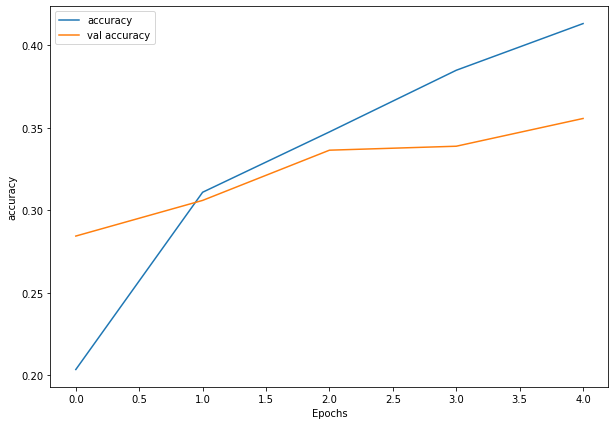
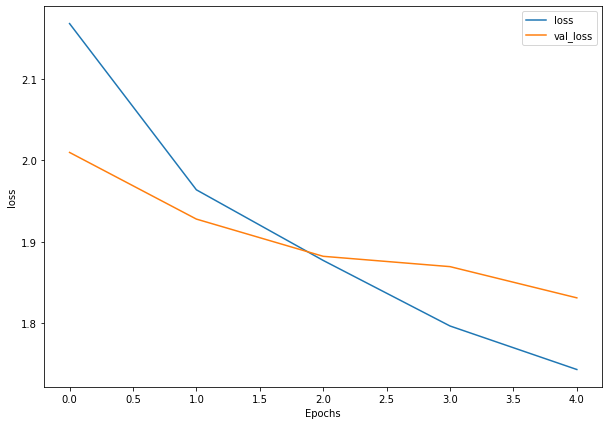
Woah, that’s quite the gap between the training and validation loss curves.
What does this tell us?
It seems our model is overfitting the training set quite badly. In other words, it’s getting great results on the training data but fails to generalize well to unseen data and performs poorly on the test data.
6. Adjust the model parameters
Due to its performance on the training data, it’s clear our model is learning something. However, performing well on the training data is like going well in the classroom but failing to use your skills in real life.
Ideally, we’d like our model to perform as well on the test data as it does on the training data.
So our next steps will be to try and prevent our model overfitting. A couple of ways to prevent overfitting include:
- Get more data - Having more data gives the model more opportunities to learn patterns, patterns which may be more generalizable to new examples.
- Simplify model - If the current model is already overfitting the training data, it may be too complicated of a model. This means it’s learning the patterns of the data too well and isn’t able to generalize well to unseen data. One way to simplify a model is to reduce the number of layers it uses or to reduce the number of hidden units in each layer.
- Use data augmentation - Data augmentation manipulates the training data in a way so that’s harder for the model to learn as it artificially adds more variety to the data. If a model is able to learn patterns in augmented data, the model may be able to generalize better to unseen data.
- Use transfer learning - Transfer learning involves leverages the patterns (also called pretrained weights) one model has learned to use as the foundation for your own task. In our case, we could use one computer vision model pretrained on a large variety of images and then tweak it slightly to be more specialized for food images.
If you’ve already got an existing dataset, you’re probably most likely to try one or a combination of the last three above options first.
Since collecting more data would involve us manually taking more images of food, let’s try the ones we can do from right within the notebook.
How about we simplify our model first?
To do so, we’ll remove two of the convolutional layers, taking the total number of convolutional layers from four to two.
How about data augmentation?
Data augmentation makes it harder for the model to learn on the training data and in turn, hopefully making the patterns it learns more generalizable to unseen data.
To create augmented data, we’ll recreate a new ImageDataGenerator instance, this time adding some parameters such as rotation_range and horizontal_flip to manipulate our images.
# Create augmented data generator instance
train_datagen_augmented = ImageDataGenerator(rescale=1/255.,
rotation_range=20, # note: this is an int not a float
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
train_data_augmented = train_datagen_augmented.flow_from_directory(train_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
Found 7500 images belonging to 10 classes.
# Clone the model (use the same architecture) or we can use the function we wrote
model_5 = tf.keras.models.clone_model(model_4)
# Compile the cloned model (same setup as used for model_10)
model_5.compile(loss="categorical_crossentropy",
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
# Fit the model
history_5 = model_5.fit(train_data_augmented, # use augmented data
epochs=5,
steps_per_epoch=len(train_data_augmented),
validation_data=test_data,
validation_steps=len(test_data))
Epoch 1/5
235/235 [==============================] - 114s 482ms/step - loss: 2.2427 - accuracy: 0.1529 - val_loss: 2.1375 - val_accuracy: 0.1992
Epoch 2/5
235/235 [==============================] - 122s 517ms/step - loss: 2.1296 - accuracy: 0.2281 - val_loss: 2.0057 - val_accuracy: 0.2932
Epoch 3/5
235/235 [==============================] - 112s 476ms/step - loss: 2.0605 - accuracy: 0.2669 - val_loss: 1.8838 - val_accuracy: 0.3384
Epoch 4/5
235/235 [==============================] - 113s 482ms/step - loss: 2.0006 - accuracy: 0.2973 - val_loss: 1.8366 - val_accuracy: 0.3672
Epoch 5/5
235/235 [==============================] - 112s 478ms/step - loss: 1.9515 - accuracy: 0.3184 - val_loss: 1.7940 - val_accuracy: 0.3896
You can see it each epoch takes longer than the previous model. This is because our data is being augmented on the fly on the CPU as it gets loaded onto the GPU, in turn, increasing the amount of time between each epoch.
How do our model’s training curves look?
# Check out our model's performance with augmented data
plot_loss(history_5)
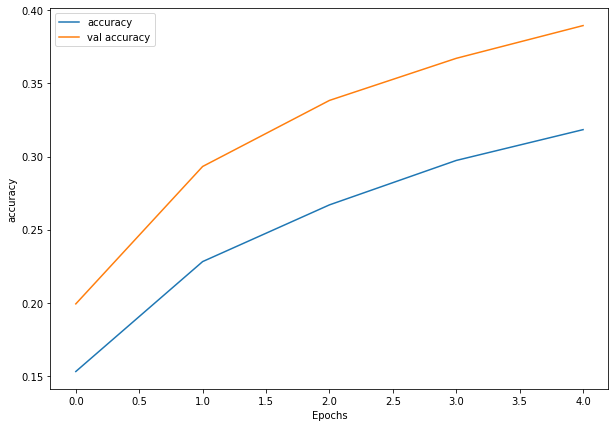
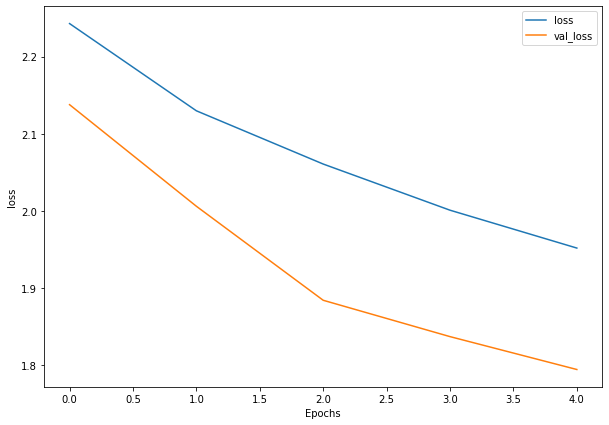
Woah! That’s looking much better, the loss curves are much closer to eachother. Although our model didn’t perform as well on the augmented training set, it performed much better on the validation dataset.
It even looks like if we kept it training for longer (more epochs) the evaluation metrics might continue to improve.
7. Repeat until satisfied
We could keep going here. Restructuring our model’s architecture, adding more layers, trying it out, adjusting the learning rate, trying it out, trying different methods of data augmentation, training for longer. But as you could image, this could take a fairly long time.
Let’s make a prediction with our trained multi-class model.
Making a prediction with our trained model
What good is a model if you can’t make predictions with it?
Let’s first remind ourselves of the classes our multi-class model has been trained on and then we’ll download some of own custom images to work with.
# What classes has our model been trained on?
class_names
array(['chicken_curry', 'chicken_wings', 'fried_rice', 'grilled_salmon',
'hamburger', 'ice_cream', 'pizza', 'ramen', 'steak', 'sushi'],
dtype='<U14')
Beautiful, now let’s get some of our custom images.
If you’re using Google Colab, you could also upload some of your own images via the files tab.
# -q is for "quiet"
!wget -q https://gitlab.com/arminny/ml_course_datasets/-/raw/main/03-steak.jpeg
!wget -q https://gitlab.com/arminny/ml_course_datasets/-/raw/main/03-hamburger.jpeg
!wget -q https://gitlab.com/arminny/ml_course_datasets/-/raw/main/03-sushi.jpeg
Okay, we’ve got some custom images to try, let’s use the pred_and_plot function to make a prediction with model_11 on one of the images and plot it.
# Create a function to import an image and resize it to be able to be used with our model
def load_and_prep_image(filename, img_shape=224):
"""
Reads an image from filename, turns it into a tensor
and reshapes it to (img_shape, img_shape, colour_channel).
"""
# Read in target file (an image)
img = tf.io.read_file(filename)
# Decode the read file into a tensor & ensure 3 colour channels
# (our model is trained on images with 3 colour channels and sometimes images have 4 colour channels)
img = tf.image.decode_image(img, channels=3)
# Resize the image (to the same size our model was trained on)
img = tf.image.resize(img, size = [img_shape, img_shape])
# Rescale the image (get all values between 0 and 1)
img = img/255.
return img
def pred_and_plot(model, filename, class_names):
"""
Imports an image located at filename, makes a prediction on it with
a trained model and plots the image with the predicted class as the title.
"""
# Import the target image and preprocess it
img = load_and_prep_image(filename)
# Make a prediction
pred = model.predict(tf.expand_dims(img, axis=0))
# Get the predicted class
if len(pred[0]) > 1: # check for multi-class
pred_class = class_names[pred.argmax()] # if more than one output, take the max
else:
pred_class = class_names[int(tf.round(pred)[0][0])] # if only one output, round
# Plot the image and predicted class
plt.imshow(img)
plt.title(f"Prediction: {pred_class}")
plt.axis(False);
# Make a prediction using model_5
pred_and_plot(model=model_5,
filename="03-steak.jpeg",
class_names=class_names)

pred_and_plot(model_5, "03-sushi.jpeg", class_names)

pred_and_plot(model_5, "03-hamburger.jpeg", class_names)

Our model’s predictions aren’t very good, this is because it’s only performing at ~35% accuracy on the test dataset.
Saving and loading our model
Once you’ve trained a model, you probably want to be able to save it and load it somewhere else.
To do so, we can use the save and load_model functions.
# Save a model
model_5.save("saved_trained_model")
# Load in a model and evaluate it
loaded_model_11 = tf.keras.models.load_model("saved_trained_model")
loaded_model_11.evaluate(test_data)
79/79 [==============================] - 11s 136ms/step - loss: 1.7940 - accuracy: 0.3896
[1.793988823890686, 0.38960000872612]
# Compare our unsaved model's results (same as above)
model_5.evaluate(test_data)
79/79 [==============================] - 11s 135ms/step - loss: 1.7940 - accuracy: 0.3896
[1.7939881086349487, 0.38960000872612]
Reference
[1] Neural Network Regression with TensorFlow
[2] Neural Network Classification with TensorFlow
[3] Milestone Project 3: Time series forecasting in TensorFlow
[4] Tensorflow Documentation for Python